AReaL 2.0 с открытым исходным кодом создаёт инфраструктуру для самообучающихся агентов через обучение с подкреплением в реальных сценариях
AReaL 2.0 с открытым исходным кодом создаёт инфраструктуру для самообучающихся агентов через обучение с подкреплением в реальных сценариях. Фото: из архива компании
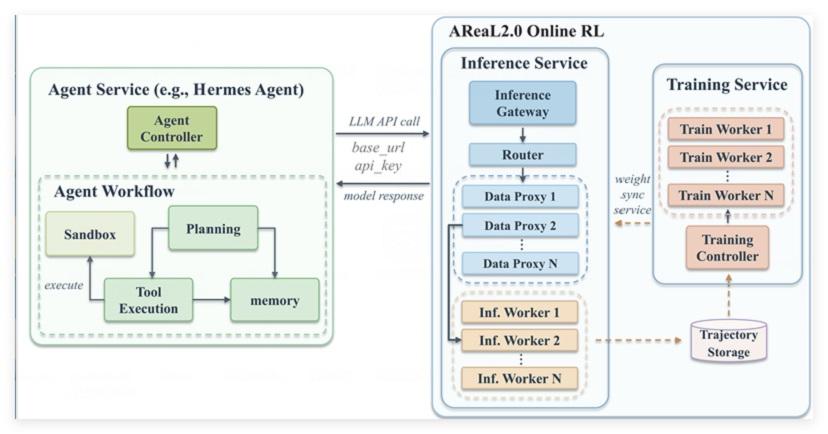
Теперь разработчикам не нужно переписывать логику агента, а достаточно перенаправить его запросы к большим моделям через единый вход AReaL 2.0, чтобы все многоэтапные диалоги, вызовы инструментов и результаты выполнения задач автоматически записывались, структурировались и интегрировались в процесс непрерывного онлайн-обучения без необходимости остановки сервиса.
Ключевая проблема, которую решает AReaL 2.0, заключается в том, что сегодняшние агенты ежедневно генерируют огромные объёмы ценного опыта — успешные стратегии, ошибки при вызове инструментов, реакции пользователей и сбои в цепочках решений — однако эти данные остаются в виде логов и почти никогда не превращаются в улучшение модели, причём в корпоративных системах, где агенты взаимодействуют с конфиденциальными данными, клиентскими базами и внутренними репозиториями, простое «собрать и переобучить» невозможно без контроля доступа, анонимизации и аудита.
Архитектура AReaL 2.0 строится на трёх фундаментальных компонентах. Стандартизированный протокол траекторий агента записывает каждое действие с метаданными о версии модели, инструментах и контексте, позволяя определять, какой именно шаг привёл к успеху или неудаче; слой Data Proxy перехватывает и обезличивает данные в реальном времени, фильтруя траектории по правам доступа, прежде чем они попадут в очередь обучения.
Control Plane принимает решение о том, когда и как обновлять модель, отличая временную ошибку инструмента от систематического сбоя, требующего переобучения через RL, и управляет канареечным развёртыванием и откатом обновлений.
При этом подход «RL как микросервис» позволяет развернуть обучение как отдельный слой, который одновременно обслуживает несколько агентных фреймворков — от Hermes до специализированных корпоративных решений, — а команда разработчиков уже подтвердила эффективность подхода в программных инженерных задачах, где онлайн-обучение на реальных траекториях значительно улучшило способность агентов адаптироваться к обновляющимся базам кода и бизнес-логике.
Комментариев пока не было